An obstacle most people face when writing academic research papers is finding similar papers easily. I faced this problem myself because it took too much time to do so.
So, I built a Python script powered by AI to search for related keywords in an input abstract and then get related abstracts on Arxiv.
What is Arxiv?
ArXiv is an open-access archive for nearly 2.4 million academic articles in physics, mathematics, computer science, quantitative biology, quantitative finance, statistics, electrical engineering and systems science, and economics.
Why choose Arxiv?
Simply because it already contains a lot of articles and a free built-in API, which makes it easier to access any article’s abstract directly. This bypasses the need to search the web using paid APIs for articles and then check if they contain an abstract, and if they do use an HTML parser to find the abstract — TOO MUCH WORK 🫠
How The API Works
http://export.arxiv.org/api/query?search_query=all:{abstract_topic}&start=0&max_results={max_results}Enter your abstract’s topic instead of {abstract_topic}, and how many search results you want instead of {max_results}. Then, paste it into the web browser, and it’ll generate an XML file containing the summary (which is the abstract) and some other details about the article, like its ID, the authors, etc…
My Implementation
The idea is simple; here’s the workflow:
1- Extract from the input abstract the top 5 keywords (topics) that are most representative of its content.
2- Call the API on each of the 5 keywords we extracted
3- Analyze the results and check the similarity of these abstracts to the input abstract.
Step 1: Extract Top Keywords
To use Arxiv’s API, we need a keyword to search for, so we need to extract the top keywords present in the input abstract. You can either use built-in libraries like nltk or spacy, but when I tried using them, the results were not as expected and not so accurate.
So, to get better results, I used OpenAI’s GPT-4 (you can use Gemini if you prefer it), gave it a power prompt, and generated optimal results. Here’s the code:
def extract_keywords(abstract):
# Constructing a prompt for the language model to generate keywords from the abstract
prompt = f"""
### TASK
You are an expert in text analysis and keyword extraction. Your task is to analyse an abstract I'm going to give you
and extract from it the top 5 keywords that are most representative of its content. Then you're going to generate
them in a JSON format in descending order from the most relevant to the least relevant.
### INPUTS
Abstract: {abstract}
### OUTPUT
The output should be in JSON format. Here's how it should look like:
[
{{"theme": "[theme 1]"}},
{{"theme": "[theme 2]"}},
{{"theme": "[theme 3]"}},
{{"theme": "[theme 4]"}},
{{"theme": "[theme 5]"}}
]
"""
# Creating an instance of the language model using SimplerLLM
llm_instance = LLM.create(provider=LLMProvider.OPENAI, model_name="gpt-4")
# Generating response from the language model
response = llm_instance.generate_text(user_prompt=prompt)
# Attempting to parse the response as JSON
try:
response_data = json.loads(response)
return json.dumps(response_data, indent=2)
except json.JSONDecodeError:
# Returning an error message if the response is not valid JSON
return json.dumps({"error": "Invalid response from LLM"}, indent=2)This function uses SimplerLLM, which facilitates the process of calling OpenAI’s API without writing tedious code. In addition, it makes it very easy for you to use Gemini’s API instead of OpenAI by only changing the name of the LLM instance like this:
llm_instance = LLM.create(provider=LLMProvider.GEMINI, model_name="gemini-pro")
Very nice, right?😉
Back to our code.
The power prompt I crafted is the main engine of the above function, so if it weren’t efficiently crafted, the code wouldn’t work at all.
### TASK
You are an expert in text analysis and keyword extraction. Your task is to analyse an abstract I'm going to give you and extract from it the top 5 keywords that are most representative of its content. Then you're going to generate them in a JSON format in descending order from the most relevant to the least relevant.
### INPUTS
Abstract: {abstract}
### OUTPUT
The output should be in JSON format. Here's how it should look like:
[
{{"theme": "[theme 1]"}},
{{"theme": "[theme 2]"}},
{{"theme": "[theme 3]"}},
{{"theme": "[theme 4]"}},
{{"theme": "[theme 5]"}}
]As you can see, it is a detailed prompt that is very well crafted to generate a specific result. By becoming a Prompt Engineer, you can learn how to craft similar prompts yourself.
Step 2: API call on each of the 5 keywords extracted
After running the above function, we’ll have a JSON-formatted output containing 5 keywords. So, we need to search for abstracts for each of the 5 keywords, and we’ll do that using Arxiv’s API.
However, when you run Arxiv’s API call, you get an XML file like this:
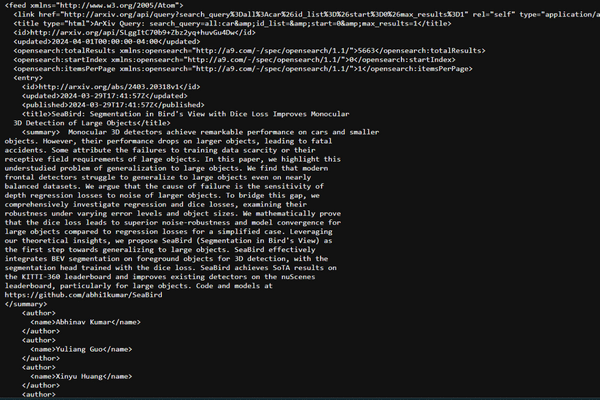
So, to easily extract the ID and summary (abstract), we’ll import xml.etree.ElementTree that helps us easily navigate and extract information from XML-formatted text.
def get_abstracts(json_input):
input_data = json.loads(json_input)
all_summaries_data = []
for theme_info in input_data:
keyword = theme_info['theme']
max_results = 1 # Number of results to fetch for each keyword
# Constructing the query URL for the arXiv API
url = f"http://export.arxiv.org/api/query?search_query=all:{keyword}&start=0&max_results={max_results}&sortBy=submittedDate&sortOrder=descending"
response = requests.get(url)
if response.status_code == 200:
root = ET.fromstring(response.text)
ns = {'atom': 'http://www.w3.org/2005/Atom'}
summaries_data = []
for entry in root.findall('atom:entry', ns):
arxiv_id = entry.find('atom:id', ns).text.split('/')[-1]
summary = entry.find('atom:summary', ns).text.strip()
summaries_data.append({"ID": arxiv_id, "abstract": summary, "theme": keyword})
all_summaries_data.extend(summaries_data[:max_results])
else:
print(f"Failed to retrieve data for theme '{keyword}'. Status code: {response.status_code}")
json_output = json.dumps(all_summaries_data, indent=2)
return json_outputIn the above function, we loop over the 5 keywords we generated, calling the API for each one, extracting the ID and abstract from the XML, saving them in a list, and formatting this list into JSON (easier to read).
Step 3: Analyze the results and check for similarity
How can we check for similarity between 2 abstracts? Again, AI 🤖
We’ll be using SimplerLLM again to create an OpenAI instance and a power prompt to perform the analysis and similarity checking.
def score_abstracts(abstracts, reference_abstract):
new_abstracts = json.loads(abstracts)
scored_abstracts = []
for item in new_abstracts:
prompt = f"""
### TASK
You are an expert in abstract evaluation and English Literature. Your task is to analyze two abstracts
and then check how similar abstract 2 is to abstract 1 in meaning. Then you're gonna generate
a score out of 10 for how similar they are. 0 being have nothing in common on different topics, and 10
being exactly the same. Make sure to go over them multiple times to check if your score is correct.
### INPUTS
Abstract 1: {reference_abstract}
Abstract 2: {item["abstract"]}
### OUTPUT
The output should be only the number out of 10, nothing else.
"""
llm_instance = LLM.create(provider=LLMProvider.OPENAI, model_name="gpt-4")
# Generating the similarity score from the language model
response = llm_instance.generate_text(user_prompt=prompt)
# Extracting the score from the response and handling potential errors
try:
score = int(response)
perfect_match = score == 10
except ValueError:
score = 0
perfect_match = False
scored_abstracts.append({
"ID": item["ID"],
"theme": item["theme"],
"score": score,
"perfect_match": perfect_match
})
return scored_abstractsWe’re gonna use the JSON output we got from the function above containing all abstracts and IDs, and we’ll loop over each abstract, run the power prompt on it with the input abstract, and get the similarity score.
As mentioned above, the power prompt is a crucial part of the function; if it is bad, the code won’t work. So, read this article to improve your prompt crafting skills.
After getting the score, if it is 10/10, then the abstract we found is a perfect match for the input abstract.
Executing The Script
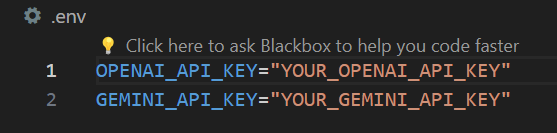
To run the codes, you’re gonna have to create a .env file that contains your OpenAI API key or Gemini key like this:
And, of course, you’ll need to enter your input abstract to run the code on it:
# MAIN SCRIPT reference_abstract = """ YOUR_ABSTRACT """ json_data = extract_keywords(reference_abstract) abstracts = get_abstracts(json_data) data = json.dumps(score_abstracts(abstracts, reference_abstract),indent=2) print(data)
Plus, don’t forget to install all the necessary libraries, which you can install by running this in the terminal:
pip install requests simplerllm
Advanced Technique
Now, although the script we created is working properly, why don’t we improve it a little?
The search for abstracts is limited to only Arxiv, and maybe there is a very similar copy to your abstract that is not available on Arxiv but on a different website. So, why don’t we tweak the code a little and make it search on Google directly for similar abstracts, and then turn it into a tool with a nice UI?
To do that, we’ll only need to update the get_abstracts Function:
# Search for related abstracts according to keywords and get link and content
def get_google_results(json_input):
keywords = json.loads(json_input)
search_results = []
for theme_info in keywords:
keyword = theme_info['theme']
query = f"{keyword} AND abstract AND site:edu AND -inurl:pdf"
result = search_with_value_serp(query, num_results=1)
for item in result:
try:
url = str(item.URL)
load = load_content(url) # Assumes load_content is a function that fetches content from the URL
content = load.content
search_results.append({"Link": url, "Content": content, "theme": keyword})
except Exception as e:
print(f"An error occurred with {url}: {e}")
continue
json_output = json.dumps(search_results, indent=2)
return json_outputAs you can see, the function now searches on Google using the search_with_value_serp The function is integrated into the SimplerLLM library. Then, I used the load_content function, which is also in the SimplerLLM library. This makes it very easy to access the link’s title and content.
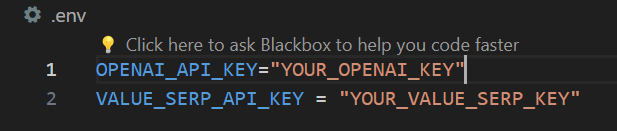
In addition, you have to add your VALUE_SERP_API_KEY in the .env file. This is how it will look like:
Keep in mind that some keywords may not have an abstract similar to it on Google so that the search would return nothing. Therefore, you might get less than 5 links for similar abstracts.
Make Money Using The Code!

The code above is only a prototype showing a headstart of this function. You can improve it to get better results, design a nice User Interface for it, and make a fully functional tool out of it. Then, you can build a SAAS business based on this tool.
In this way, you’ll have a monthly recurring income from these tools you built! Pretty nice, huh 😉
Remember, if you have any questions, make sure to drop them below in the comments section or on the forum.
