Today, I will show you two approaches to building an AI-powered Semantic Router.
An AI router is a component used mainly in AI Agents that directs incoming requests to the appropriate functions/actions.
In simpler terms, it takes a user’s query and redirects the AI Agent to the right place, which helps get the best solution for the user’s problem.
In this post, I’ll be building an API semantic router that takes a user inquiry and helps choose the most suitable API that would help solve the user’s problem.
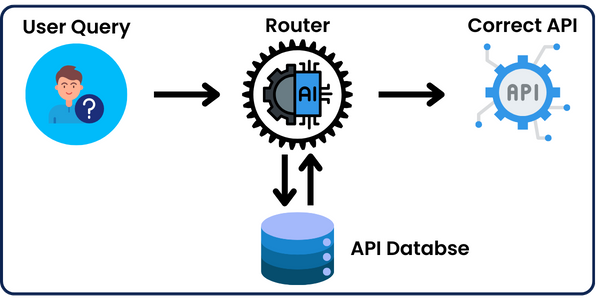
I’ll be implementing it in 2 approaches:
- Approach 1: LLMs (Large Language Models_)
- Approach 2: Vector Databases and Semantic Similarity.
I’ll be going over each implementation, explaining the idea, and in the end, I’ll compare all the results we got and analyze them. (I’ll share all the resources I used; don’t worry)
The Implementations
The idea behind both implementations is to take a user query, such as “I want to track my fitness journey and transformation.”
Then, the semantic router will check whether we have an API in our list that can help track the user’s fitness journey.
💡I saved the list of 20 APIs in a json file to make it easier to access the APIs' title and description when loading it to our script💡Regardless of the method chosen, we’ll need to set up our system to run the codes properly. So, we’ll need to install the necessary libraries and create a virtual environment to help isolate the project and avoid conflicts between package versions.
So, open a new terminal and run the following step-by-step:
1- Create the Virtual Environment:
python - m venv venv
2- Create and Activate the Virtual Environment:
venv/scripts/activate
3- Install Libraries:
pip install simplerllm
As you can see, the only library needed is SimplerLLM, which makes building AI tools much more straightforward.
After that, it’s time to create a .env file in your project folder to add your OpenAI API Key so that the SimplerLLM functions can use it to generate the responses.
If you don’t have an API key, go to OpenAI’s website and generate a new one. Then, add it to the .env file in this form:
OPENAI_API_KEY = "YOUR_API_KEY"
Now, we’re ready to get into the codes’ details.
Approach 1: LLMs
This approach involves taking the user and the list of APIs with their respective titles and descriptions.
We’ll then feed the query and the list to a power prompt and then to an LLM (AI-Language Model), which will check if there’s an API that would solve the query; otherwise, it will return None.
The code is based on two functions: one that fetches the APIs from the json file so we can integrate them into our prompt, and the other integrates the user query and APIs into the power prompt and generates the response using OpenAI’s GPT model.
Fetching the APIs
def fetch_apis(filepath):
text_file = load_content(filepath)
content = json.loads(text_file.content)
return contentAs you can see, it’s very simple; we’re using SimplerLLM’s load_content function, which loads the file content into our script.
Finding the Best API
def find_best_api(user_query, api_descriptions):
llm_instance = LLM.create(provider=LLMProvider.OPENAI, model_name="gpt-4o-mini")
u_prompt = f"""
You are an expert in problem solving. I have a user specific query and I want to check if I have an API
that would help him solve this problem. I'll give you both the user inquery and the list of APIs in the inputs
section delimited between triple backticks. So analyze both of them very well and check if there's an API which
can help him or no.
##Inputs
user inquiry: ```[{user_query}]```
API list: ```[{api_descriptions}]```
#Output
The output should only be the API name as provided in the inputs and nothing else. If no API was found return None.
"""
response = llm_instance.generate_response(prompt=u_prompt)
return responseThe power prompt is the main part of this function, where we integrate the user query and the list of APIs. Then, using SimplerLLM’s functions, we check if there’s a suitable API to help with the user inquiry.
Let’s try it and see the results:

As you can see, It correctly chose the API that best fits the user inquiry.
Let’s try another one:

“No suitable API found.” Let’s manually check our list of APIs and see if that’s correct:
[
{
"name": "Weather API",
"description": "Provides real-time weather information including forecasts, current weather conditions, and historical data for any location in the world."
},
{
"name": "Translation API",
"description": "Offers instant text translation capabilities between multiple languages, supporting over one hundred languages with various dialects."
},
{
"name": "Finance API",
"description": "Delivers up-to-date financial data such as stock prices, market trends, and investment insights, suitable for building financial applications or integrating into existing systems."
},
{
"name": "Email Verification API",
"description": "Verifies email addresses in real-time to ensure they are valid and capable of receiving emails, improving email campaign deliverability."
},
{
"name": "Food Nutrition API",
"description": "Provides detailed nutritional information for a vast array of foods, including calorie counts, macronutrients, and micronutrients."
},
{
"name": "News API",
"description": "Aggregates current and historical news articles from various sources worldwide, providing rich filters to fetch news by topic, language, or region."
},
{
"name": "GeoCoding API",
"description": "Converts addresses into geographic coordinates and vice versa, enabling location-based services and applications."
},
{
"name": "Music Discovery API",
"description": "Enables discovery of music based on artist, genre, or mood through its extensive music database and recommendations system."
},
{
"name": "Vehicle Data API",
"description": "Offers detailed information about various vehicle models, including specifications, pricing, and safety ratings."
},
{
"name": "Public Holidays API",
"description": "Provides information on public holidays worldwide, including upcoming holidays and historical data by country."
},
{
"name": "OCR API",
"description": "Converts images of text into editable and searchable data, supporting multiple languages and script types."
},
{
"name": "Barcode Lookup API",
"description": "Allows for the identification and lookup of products using their barcode numbers, providing product details and pricing information."
},
{
"name": "AI Image Enhancement API",
"description": "Enhances image quality through AI-powered algorithms, improving resolution, reducing noise, and correcting lighting."
},
{
"name": "Fitness Tracking API",
"description": "Gathers and analyzes data from fitness devices, helping users monitor their health and fitness activity."
},
{
"name": "Movie Database API",
"description": "Accesses a vast database of films, including details on cast, crew, plot summaries, and box office statistics."
},
{
"name": "Text-to-Speech API",
"description": "Converts text into natural sounding speech in multiple languages, useful for creating audio content from text sources."
},
{
"name": "Flight Data API",
"description": "Tracks flight status in real-time, including departures, arrivals, delays, and cancellations across global airlines and airports."
},
{
"name": "Job Search API",
"description": "Aggregates job listings from multiple sources, providing tools to search by keyword, location, and job type."
},
{
"name": "Cryptocurrency API",
"description": "Delivers real-time and historical data on cryptocurrencies, including prices, market cap, trade volume, and exchange info."
},
{
"name": "Face Recognition API",
"description": "Provides facial recognition services to identify or verify individuals from an image or video."
}
]Upon revision, we can conclude that the router was right and that no API can help the user with their query.
Running the Script
For the script to work, you only need to copy the above list of APIs and save it as apis.json in your project folder.
Then, when you run the code, you enter your query in the terminal and let the script fetch the most suitable API for you.
Approach 2: Vector Databases and Semantic Similarity
This approach is the same as the AI router; however, in the main function, instead of using a power prompt to find the most suitable API, we’re getting the text embeddings of all the APIs and saving each with their respective API title and description in a vector database using our customized code of Simpler Vectors Library.
What are Vector Databases?
If you know what vector databases are, feel free to skip this section.
A Vector Database is a specialized database designed to handle and search through high-dimensional vector data. It does not just include the 2—or 3-dimensional spaces we know; it can go up to 300 dimensions or even more.
Vector databases are crucial in applications like recommendation systems, image search, and natural language processing.
In simple terms, it allows computers to efficiently find similar vectors (like embedding vectors) among millions of others. Vector embeddings are numerical representations of data (like words or images) in high-dimensional space that capture their meanings, relationships, and properties for machine learning tasks.
Here’s a simplified version of a vector database in 3 dimensions:
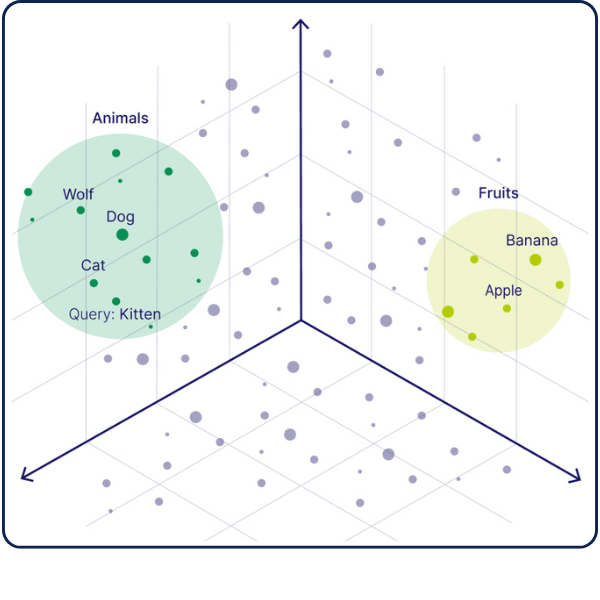
It is visually impossible to represent a 300-dimensional space. That’s why figures in vector databases are usually visualized in 3 dimensions.
Instead of searching for exact matches like traditional databases, vector databases use algorithms like cosine similarity to find vectors that are “close” in the distance within the vector space.
This makes vector databases essential for tasks like searching similar images, finding related articles, or suggesting relevant products.
In our case, we’ll use a vector database to store and query API titles and descriptions, allowing us to return the most suitable API based on the user’s query and problem context.
Let’s take the ‘Fitness Tracking API’ as an example and see how it’s saved in the vector database:
([0.1, 0.43, 0.21, 0.91, …], {“api”: ‘Fitness Tracking API’, “description”: ‘Gathers and analyzes data from fitness devices, helping users monitor their health and fitness activity.’})
As you can see, the first value is the text embedding of the description, and then we have the API title followed by its description. (the text embedding shown isn’t the real value it’s just an example)
After that, when the user enters their query, it’s converted into a text embedding.
Then, we extract the API whose text embedding has the top cosine similarity with the text embedding of the user query.
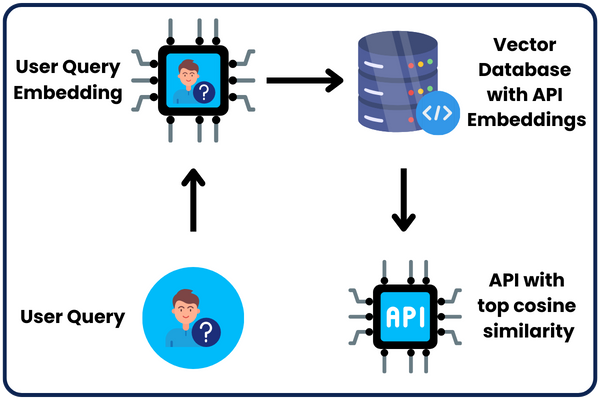
If the cosine similarity is greater than 0.3 (the threshold we chose), the two vectors are similar in meaning; then the API is suitable for solving the user query; therefore, we return it; otherwise, it will return None.
💡 The threshold I chose is just for testing; if you want to apply a more accurate one, you’ll have to do your own research to determine what would be best in this case.The code is based on three functions:
- Function 1: Fetches the APIs from the json file so we can save them in the vector database.
- Function 2: Turns the API descriptions into text embeddings.
- Function 3: Save the data in a vector database and fetch the most suitable API.
Fetching the APIs
def fetch_apis(filepath):
text_file = load_content(filepath)
content = json.loads(text_file.content)
return [(api['name'], api['description']) for api in content] It’s the same function used before, with a little tweak, where the data is returned in a list form.
This makes the data more flexible to use when converting the descriptions to text embeddings and saving the APIs in a vector database.
Generate Embeddings
def get_embeddings(texts):
try:
embeddings_instance = EmbeddingsLLM.create(provider=EmbeddingsProvider.OPENAI, model_name="text-embedding-3-small")
response = embeddings_instance.generate_embeddings(texts)
embeddings = np.array([item.embedding for item in response])
return embeddings
except Exception as e:
print("An error occurred:", e)
return np.array([])This is the function we’ll use to get the text embeddings of the APIs’ descriptions. As you can see, SimplerLLM is very straightforward; it takes a list of descriptions and returns their respective embeddings using OpenAI’s Text Embedding Model.
Finding the Best API
def find_best_api(user_query, apis):
db = VectorDatabase('VDB')
api_descriptions = [api[1] for api in apis]
query_embedding = get_embeddings([user_query])
description_embeddings = get_embeddings(api_descriptions)
for idx, emb in enumerate(description_embeddings):
db.add_vector(emb, {"api": apis[idx][0], "description": apis[idx][1]}, normalize=True)
query_embedding = db.normalize_vector(query_embedding[0])
best_sim = db.top_cosine_similarity(query_embedding, top_n=1)
top_match = best_sim[0]
if top_match[1] > 0.3:
return best_sim[0]
else:
return NonThis is the main engine of the code, where we use Simpler Vectors to create a vector database and add text embeddings.
Then, after we convert the user query to a text embedding, we normalize it and get the API whose cosine similarity with the user query is the largest.
💡 Normalizing vector embeddings to unit length before calculating cosine similarity ensures the similarity reflects only the angle between vectors, unaffected by their magnitude, making the comparison more accurate 💡Finally, if this cosine similarity is greater than the 0.3 threshold we chose, we return the API; otherwise, we don’t.
Running the Script
To run the script, it’s the same as the one above, except that here, we need to add the Simpler Vectors customized script to our project as well.
So, add both codes to your project folder and dive right in!
Let’s try it and see the results:

As you can see, it correctly chose the API that best fits the user inquiry and returned all the API’s details with the cosine similarity, too!
Let’s try another one:
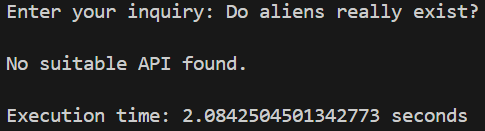
As demonstrated, this router also returned the correct result, where no API can help the user with their query.
Increase the Number of APIs
We’ve been using 20 APIs to run the routers until now. If you review the test results, you can see that the AI router took an average of approximately 1 second, while the Semantic Router took an average of approximately 2 seconds.
If we increased the number of APIs to 100, do you think the script’s execution time would change much? Let’s update our list of APIs to try and see the results.
AI Router:

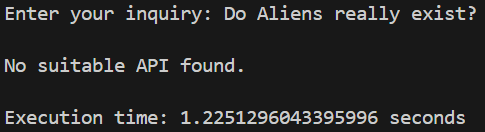
As you can see, both results are still correct. However, if you focus on the execution time, it slightly increases (+0.1 s) in both cases.
Semantic Router:

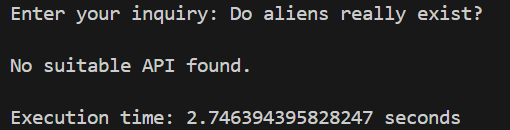
Still, both results are correct. However, the execution time increased drastically compared to when we used only 20 APIs.
Visualize the Results
Let’s take “I want to track my fitness journey and transformation” as test case 1 and “Do aliens really exist?” as test case 2.
| Factors | Test Case 1 (20 APIs) | Test Case 2 (20 APIs) | Test Case 1 (100 APIs) | Test Case 2 (100 APIs) |
|---|---|---|---|---|
| AI Router | 1.4 seconds | 1.1 seconds | 1.5 seconds | 1.2 seconds |
| Semantic Router | 1.8 seconds | 2.08 seconds | 4.1 seconds | 2.7 seconds |
As demonstrated, the AI router’s execution time didn’t increase much when we quintupled (x5) the number of APIs, unlike the execution time of the semantic router, which nearly tripled in the first test case and 1.5x in the second test case.
We can’t draw a concrete conclusion from these test cases alone. However, it seems that the execution time of the semantic router will increase more rapidly with the increase in the number of APIs than that of the AI router.
This makes sense since the number of computation steps is somehow too many compared to the AI router, which only sends the prompt and gets the result.
In My Opinion
I think with a larger number of APIs (500+), the AI will start to hallucinate, especially if we don’t use the top models, since the prompt will be too large (it contains the whole list of APIs) and will give the wrong results.
💡 Hallucination is one of the main limitations of LLMs (Large Language Models) like ChatGPT, Gemini, etc... Where the LLM might generate information that sounds plausible but is incorrect or unverified. Learn more about it by becoming a Prompt Engineer💡So, in the long run, if you want a more concrete router, the semantic router would most definitely give better results, although it might take more time to run.
On the other hand, if you’re looking for a router to try on small data and you want fast results, the AI router might be better.
What about you? Do you agree with this conclusion? Share your opinion in the comments below. Moreover, if you tried it with a larger dataset, share your results with us on the forum so we can discuss them!
Different Scenarios Where You Can Deploy Semantic Routers
There are various scenarios where semantic routers play a crucial role in enhancing decision-making by guiding the software to the most optimal choice.
We’ll explore some of these scenarios in this section:
Develop Improved AI Agents
What are AI agents? They are software programs that address user queries by using external functions along with AI, thereby overcoming some AI limitations.
To improve the way these AI agents work, you can use a semantic router that helps the agent decide which function to use based on the user’s needs.
First, list all the functions your AI agent can perform, each capable of handling specific tasks. Then, the router analyzes each user query in real time and selects the most suitable function to address it.
For example, consider these scenarios:
- View Counts: When a user asks, “How many views does this YouTube video have?” the router identifies the query’s intent and selects the YouTube API function to retrieve the video’s view count directly from YouTube.
- Video Summary: If a user requests a summary of a video, the router calls the summarization function, which uses a power prompt to generate a summary based on the video’s script.
- Specific Scenario Inquiry: For questions about particular parts of a video, the router chooses a function that uses a vector database. It finds the part of the video script that best matches the query (highest cosine similarity) and returns that segment as the answer.
By regularly updating your list of functions and improving how the router matches questions to functions, your AI agent will become better at helping users quickly and accurately, making it a more useful tool for everyone who uses it.
Turning the API example into a Business

Let’s start with a simple, straightforward scenario you can use to turn the list of APIs and a router into a profitable business model.
First, you’ll need to modify your existing list of APIs, where each API should include a title, description, and a new feature, “link.” Here’s an example of how your API entry might look:
{
"name": "Fitness Tracking API",
"description": "Gathers and analyzes data from fitness devices, helping users monitor their health and fitness activity.",
"link": "examplelinktoapi.com"
}Next, develop a user interface for your tool where users can enter their inquiries. This interface will call the backend—our router. When a user submits a query, the router evaluates the list of APIs and selects one that best matches the user’s needs. The router then returns a link to the selected API.
This link could be an affiliate link, earning you a commission for every user who clicks through and uses the service. Alternatively, the link could direct users to an API you have developed, encouraging them to subscribe and use your API.
By following these steps—editing your API list, creating a user-friendly interface, and integrating the router—you set up a system where each user interaction has the potential to generate revenue, either through affiliate commissions or direct subscriptions.
Hello,
Is it possible to use another Embedding Provider instead?
than OPENAI. I was thinking mainly of a hugging face model.
you can use any embedding model you want. update the get embedding function