
Repurpose Content with AI & Python – A Single Click !
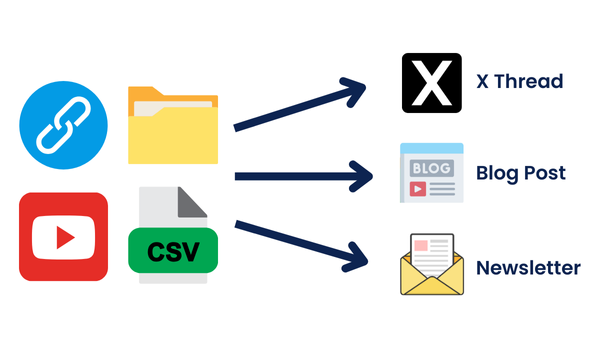
In this guide, I’ll walk you through a complete automation system that helps you repurpose content into as many other posts as you want.
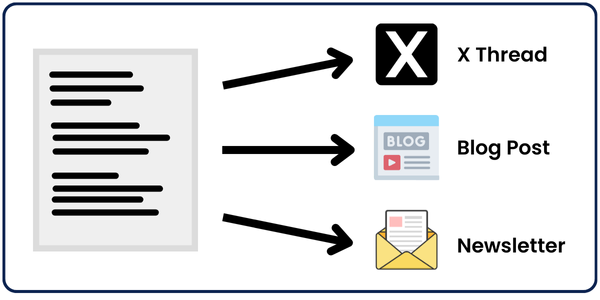
The input piece of content can be anything: a YouTube video link, a blog post link, an outline, a tweet, a pdf, etc…
I’ll provide you with all the codes at the end of this post.
Follow me step by step to understand how everything works so that you can edit the code to your liking if needed.
How Does it Work?
The main engine which repurposes these posts is our power prompts. These prompts are fed to OpenAI’s GPT model or the Models of your choice, which will do all the work for us.
In my case, I’ll be using GPT-4o, which is better than GPT-3.5 and cheaper than GPT-4.
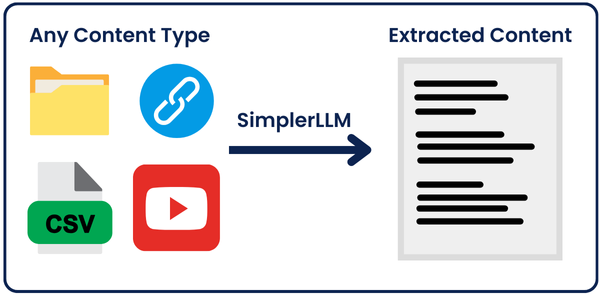
First, we’re going to extract the content from the link/file in the input.
But how can we extract any content with just one line of code?
Here comes SimplerLLM, a Python library that I recently developed. It makes coding AI Tools much easier as you will see.
From here, I’ve implemented two strategies:
Strategy 1: We take the extracted content, feed it to OpenAI’s GPT model using SimplerLLM and get one piece of repurposed content depending on the prompt we’re using.
I implemented this to make it easier for you to grasp the foundation of the main automation script.
Strategy 2: This is the main code that will take the extracted content and generate three different types of content, also using SimplerLLM.
Then, we’ll take the outputs and merge them into 1 JSON-formatted output.
Now, regardless of which code you use, the output will be saved into a txt/json file in your code’s folder.
Strategy 1: Foundation Code
By now, you should have grasped the idea behind how the code works. So, let’s get technical!
First, our code is highly dependent on SimplerLLM to make it simple and short. So, let’s start by installing the library and importing it.
Creating A Virtual Environment and Installing SimplerLLM
Open a new terminal and run the following step-by-step:
1- Create the Virtual Environment:
python - m venv venv
2- Create and Activate the Virtual Environment:
venv/scripts/activate
3- Install SimplerLLM:
pip install simplerllm
Now, we have a virtual environment with simplerllm installed, which will help isolate the project and avoid conflicts between package versions.
Try the Code
First things first, we’ll need to create a .env file and add our OpenAI API Key so that the SimplerLLM functions can use it to generate the responses.
If you don’t have an API key, go to OpenAI’s website and generate a new one. Then, add it to the .env file in this form:
OPENAI_API_KEY = "YOUR_API_KEY"
Now, we’re ready to use the code; here it is:
from SimplerLLM.tools.generic_loader import load_content
from SimplerLLM.language.llm import LLM, LLMProvider
from resources import text_to_x_thread, text_to_blog_post, text_to_medium_post, text_to_summary, text_to_newsletter
#This can take a youtube video link, a blog post link, a csv file, etc... as input too
file = load_content("https://learnwithhasan.com/create-ai-agents-with-python/")
#Edit the prompt name in accordance to what you want to convert it to
final_prompt = text_to_x_thread.format(input = file.content)
llm_instance = LLM.create(provider=LLMProvider.OPENAI, model_name="gpt-4o")
response = llm_instance.generate_response(prompt=final_prompt, max_tokens=1000)
with open("response.txt", "w", encoding='utf-8') as f:
f.write(response)
As you can see, we’ve imported two things to our code: the SimplerLLM functions we’ll use and the resources file, which I created and saved all the power prompts in, and I’ll give it to you for free!
The file variable uses the SimplerLLM function load_content that takes your link/file as input and loads its data.
So, I’ll start first by formatting my prompt and store in the final_prompt variable.
This can be done by using the text_to_x_thread prompt, which we imported from the resources file and passed along with the blog post content, as shown above.
Now, we create an OpenAI LLM instance in order to call their GPT model, and we call it using the generate_reponse function as shown in the response variable.
💡 Note that by default, this function returns a maximum of 350 tokens as output; that's why we added the max_tokens parameter to increase it to 1000 because most of our outputs will be a little long.Then, we take the response generated and save it in a response.txt file. Here’s what the output will look like:
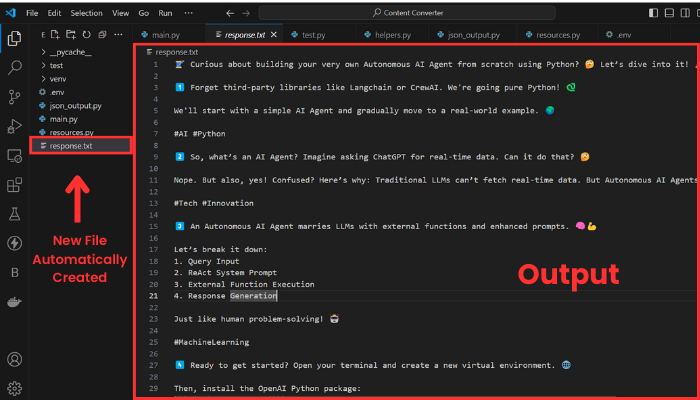
The output is composed of ten threads, and it would be too long if I wanted to show you the whole thing. Anyway, my point here is to show you that it works.
Let’s now try another example by turning a YouTube video into a blog post.
To do that, we’ll have to change the input and the prompt we’re using.
I’ll choose as input a video from Hasan’s YouTube Channel.
Here’s the edited line of code:
file = load_content("https://www.youtube.com/watch?v=DAmL-b_c85c")
To change the prompt, edit this line of code:
final_prompt = text_to_blog_post.format(input = file.content)
Let’s run it and see the output:
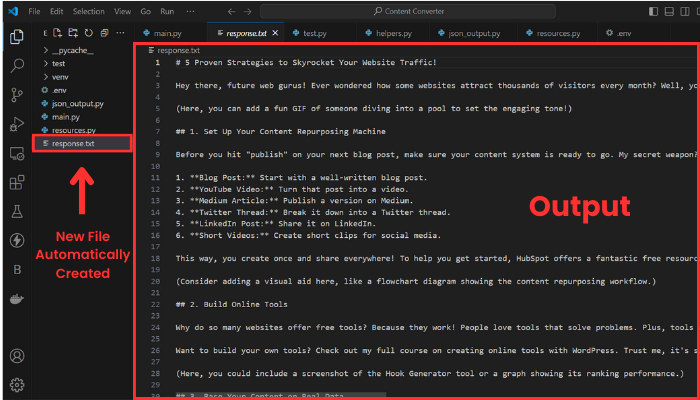
As you can see, the format changed to a blog post, and the input is now the transcript of the YouTube video.
Here are both the code we used above and the resources.py file, which contains some of my power prompts:
Strategy 2: The Main Code
Now, it’s time for the real deal, what you’ve been waiting for!
In this strategy, with a single click, you’re gonna be able to repurpose your content into three different pieces of content, all formatted in a json output, which will make them easier to access.
No new resources will be needed to use this method; all you need is the updated code. Here it is:
import json
from SimplerLLM.tools.generic_loader import load_content
from SimplerLLM.language.llm import LLM, LLMProvider
from resources import text_to_x_thread, text_to_summary, text_to_newsletter, format_to_json
llm_instance = LLM.create(provider=LLMProvider.OPENAI, model_name="gpt-4o")
#This can take a youtube video link, a blog post link, a csv file, etc... as input too
file = load_content("https://learnwithhasan.com/create-ai-agents-with-python/")
#Getting the 3 inputs
x_prompt = text_to_x_thread.format(input = file.content)
newsletter_prompt = text_to_newsletter.format(input = file.content)
summary_prompt = text_to_summary.format(input = file.content)
#Generating the 3 types of social posts
x_thread = llm_instance.generate_response(prompt = x_prompt, max_tokens=1000)
with open("twitter.txt", "w", encoding='utf-8') as f:
f.write(x_thread)
newsletter_section = llm_instance.generate_response(prompt = newsletter_prompt, max_tokens=1000)
with open("newsletter.txt", "w", encoding='utf-8') as f:
f.write(newsletter_section)
bullet_point_summary = llm_instance.generate_response(prompt = summary_prompt, max_tokens=1000)
with open("summary.txt", "w", encoding='utf-8') as f:
f.write(bullet_point_summary)
#Converting them into json format
final_prompt = format_to_json.format(input_1 = x_thread,
input_2 = newsletter_section,
input_3 = bullet_point_summary)
response = llm_instance.generate_response(prompt = final_prompt, max_tokens=3000)
# Validate and write JSON with indentation for readability
try:
json_data = json.loads(response)
with open("Json_Result.json", "w", encoding='utf-8') as f:
json.dump(json_data, f, ensure_ascii=False, indent=4)
print("JSON saved successfully.")
except json.JSONDecodeError as e:
print("Error in JSON format:", e)
with open("Json_Result.json", "w", encoding='utf-8') as f:
f.write(response)
This code’s structure is very similar to the one above; we’re using the same functions here, too.
The main difference is that instead of generating only 1 type of content, we’ll use OpenAI’s GPT model to repurpose the input of choice into three different types of content. We’ll save each output in a TXT file with its respective name.
💡 Note that you can edit the prompts here too in order to get different results, as I showed you above. If you face any obstacles we'll be here to help you on the forum!Then, after we get the three outputs, we’ll merge them into one json output using a power prompt and save them in a json file.
However, the GPT’s response doesn’t always work and generates a correct json format. That’s why I added a try-except statement so that if it doesn’t work, it prints the code and saves it as raw text.
I can’t get into the details of fixing this, but you can check this blog post; it will definitely help you improve the results.
Now, let’s try it and see what we get!
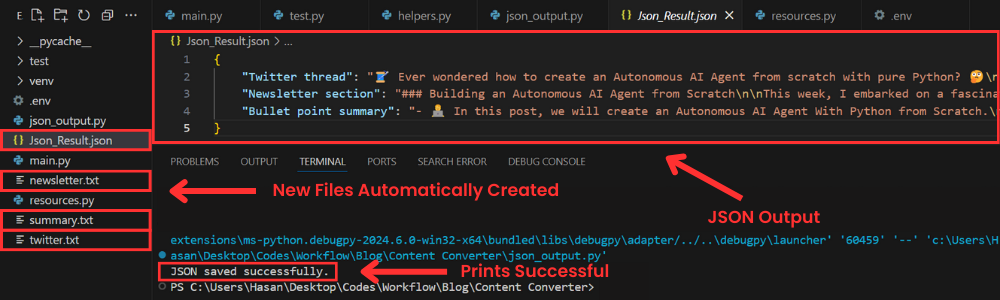
As you can see, four new files are created; 3 of them contain the three pieces of content individually generated, and a json file which contains the final json formatted output.
Play with the prompts as you like, and you’ll get new results that match your preferences. If you face any problems, don’t hesitate to ask us for help on the forum. We’ll always be there to help you.
Create a UI For The Tool
The script works perfectly in the terminal, but why don’t we build a simple, user-friendly interface that makes it easier to run the code?
Plus, people who don’t know anything about coding will be able to use it without interacting with the code at all.
This is super simple if we combine streamlit with our power prompt below:
Act as an expert Python programmer specialized in building user-friendly UIs using Streamlit.
Create a Streamlit UI for the provided script. Make sure to comment all the code to enhance understanding, particularly for beginners. Choose the most suitable controls for the given script and aim for a professional, user-friendly interface.
The target audience is beginners who are looking to understand how to create user interfaces with Streamlit. The style of the response should be educational and thorough. Given the instructional nature, comments should be used extensively in the code to provide context and explanations.
Output:
Provide the optimized Streamlit UI code, segmented by comments explaining each part of the code for better understanding.
Input:
Provided script: {your input script}This prompt is part of the premium prompt library, which is updated every month with new special prompts. All power members get access to the library.
Anyway, I used the prompt, and in seconds, I created a UI for my tool with Streamlit. Here’s the code it generated:
import streamlit as st
import json
from SimplerLLM.tools.generic_loader import load_content
from SimplerLLM.language.llm import LLM, LLMProvider
from resources import text_to_x_thread, text_to_summary, text_to_newsletter, format_to_json
llm_instance = LLM.create(provider=LLMProvider.OPENAI, model_name="gpt-4o")
st.title("Content Generation With A Single Click")
url = st.text_input("Enter the URL or File Name of your input:")
if st.button("Generate Content"):
if url:
try:
file = load_content(url)
x_prompt = text_to_x_thread.format(input=file.content)
newsletter_prompt = text_to_newsletter.format(input=file.content)
summary_prompt = text_to_summary.format(input=file.content)
x_thread = llm_instance.generate_response(prompt=x_prompt, max_tokens=1000)
newsletter_section = llm_instance.generate_response(prompt=newsletter_prompt, max_tokens=1000)
bullet_point_summary = llm_instance.generate_response(prompt=summary_prompt, max_tokens=1000)
st.subheader("Generated Twitter Thread")
st.write(x_thread)
st.markdown("---")
st.subheader("Generated Newsletter Section")
st.write(newsletter_section)
st.markdown("---")
st.subheader("Generated Bullet Point Summary")
st.write(bullet_point_summary)
st.markdown("---")
final_prompt = format_to_json.format(
input_1=x_thread,
input_2=newsletter_section,
input_3=bullet_point_summary
)
response = llm_instance.generate_response(prompt=final_prompt, max_tokens=3000)
try:
json_data = json.loads(response)
st.markdown("### __Generated JSON Result__")
st.json(json_data)
st.download_button(
label="Download JSON Result",
data=json.dumps(json_data, ensure_ascii=False, indent=4),
file_name="Json_Result.json",
mime="application/json"
)
except json.JSONDecodeError as e:
st.error(f"Error in JSON format: {e}")
st.write(response)
except Exception as e:
st.error(f"An error occurred: {e}")
else:
st.warning("Please enter a valid URL.")
The code above generates the three types of content you chose, displays them, and, at the end, the json result with a download button to download the result in 1 click.
Now, to run the code, you’ll need to save the code as ui.py, open a new terminal and run the following:
streamlit run ui.py
Of course, you can change the file’s name, but you’ll also need to change it to the new file’s name when you run it.
Once you run it, the following web page will open:
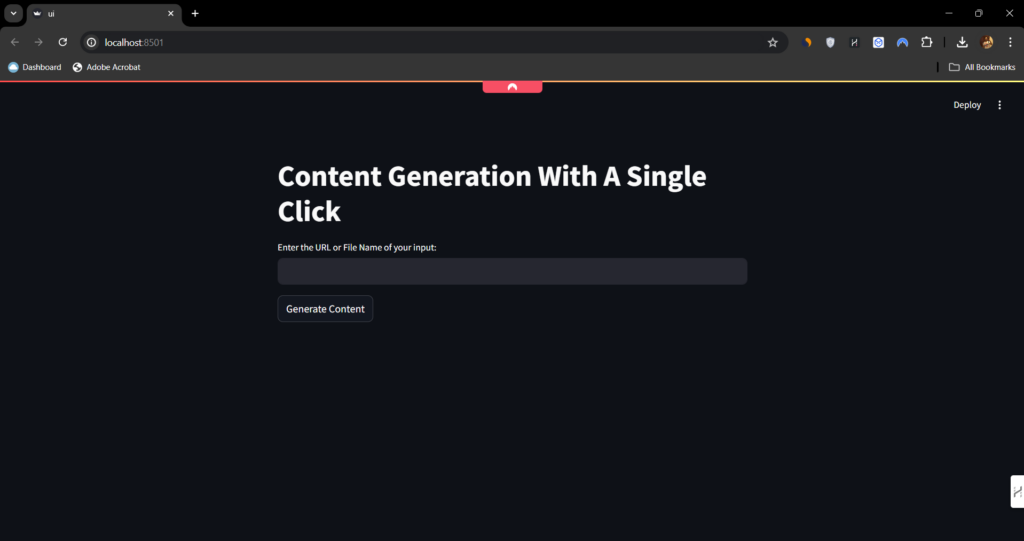
As you can see, it’s very simple and straightforward to use. You just enter the link or the name of the file and click the generate button to get all the results.
💡 Note that the json result may take a bit more time than the 3 content types to be displayed, so wait a bit till it finished running.Don’t forget, if you face any problems, don’t hesitate to post them on the forum. The team will be there to help you almost every day.
Turn This Tool Into a Money-Making Machine

Rather than keeping the tool only for your use, let people use it and charge them for every use. Let me explain:
If you build a neat user interface for your tool on your WordPress website (one of the easiest things to do), you can build a points system, and people would buy points to use these tools.
This is the technique I use on PromoterKit, where he charges people a certain number of points on every use, depending on the tool they’re using.
If you want to learn how to clone the same strategy and business model he’s using, check out this guide. It teaches you how to build a SAAS on WordPress and includes a premium forum where the team will be there to help you whenever needed!
If you’re looking for a free source, I also have you covered!
Here’s a Free Guide that teaches you how to start!
Good Luck!





Responses