In this post, I will show you how to detect the percentage of plagiarism in a piece of text. A direct, practical solution I created and tested!
The idea is very simple, and it is a perfect starting point for checking plagiarism in any piece of text. I will explain the approach step by step with a practical example, so let’s start!
How Do Plagiarism Checkers Work?
Plagiarism checkers scan for matches between your text and existing texts and give a similarity percentage at the end.
Behind the scenes, most of these tools surf the web and scan your text for similarities against existing content found on the internet.
Exact matches are highlighted easily by comparison. However, more complex checkers can also identify non-exact matches, aka paraphrased text.
But before applying all that, these plagiarism tools start by splitting text into smaller chunks like phrases, sentences, and paragraphs; notice how I didn’t say “splitting into individual words.” That’s because words are independent, resulting in a less effective plagiarism test.
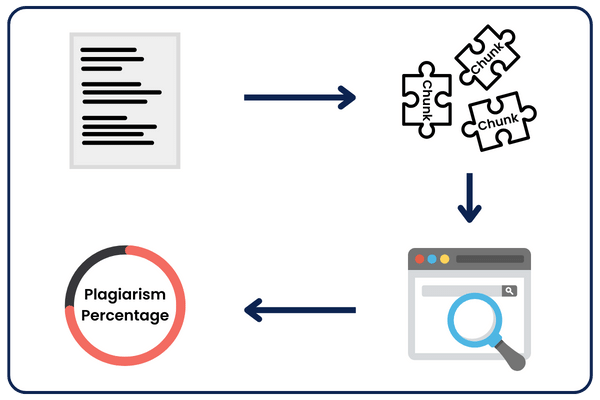
So, which chunking method should you choose?
Each approach has its pros and cons:
For example, if you choose to chunk by sentences, you’d get a more accurate result; however, the code will need more time to execute.
Moreover, this method wouldn’t be fair to apply if you’re examining someone (Teachers using it on students) because there is a probability that some general sentences may already have been used by someone on the internet, and the person didn’t copy them.
Unlike the chunking-by-paragraphs method, which would result in a less accurate result but less time to execute. This method is the go-to one when running a plagiarism detector on students.
Here are the results I got when I tried both methods:
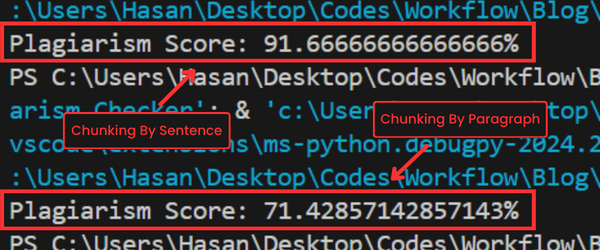
In the end, you choose the method based on your needs.
My Implementation
Let’s keep things simple with a real practical example! Here is what we need:
1- A function that takes care of the chunking of our text
2- A function that surfs the web and checks if this chunk exists
3- Add up all the results and get the percentage
Step 1: Text Chunking
Let’s make it dynamic!
def chunk_text(text, chunk_by) -> List[str]:
if chunk_by == "sentence":
sentences = re.split(r'(?<!\d)[.?!](?!\d)', text)
sentences = [sentence.strip() for sentence in sentences if sentence.strip()]
return sentences
elif chunk_by == "paragraph":
paragraphs = [paragraph.strip() for paragraph in text.split("\n") if paragraph.strip()]
return paragraphs
else:
raise ValueError("Invalid chunk_by value. Choose 'sentence' or 'paragraph'.")This function takes as input the text and your chosen chunking method, then if you choose:
- By Sentence: I used a very straightforward method: I split whenever I find a ‘.’ or ‘!’ or ‘?’ between sentences.
- By Paragraph: I used a similar approach to the one above, which splits the input whenever there’s a new line between paragraphs. In Python, the new line is defined as \n.
This dynamic approach makes it easier to switch to whichever method is based on your liking. Plus, you can see the experiment yourself and see how the accuracy changes depending on the text and method used.
Step 2: Surf the Web
Now that we have split the text into chunks, we need to take each chunk, put it between double quotes like “[chunk]”, and search for if it matches something on the internet.
Here’s an example of a unique chunk:
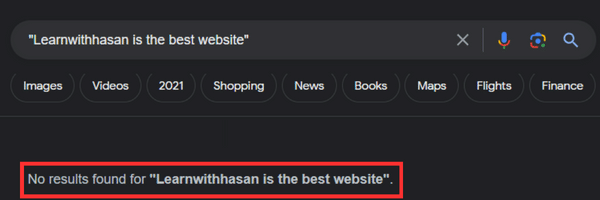
As you can see, no results were found for “Learnwithhasan is the best website” although it’s a well-known fact 😂
💡 Tip 💡 When you’re searching for an exact match of something you should delimit it between double quotes. Like this search engine you’re using knows that you’re looking for this exact phrase and not normal searching.
Back to our code:
def search_chunk(chunk) -> bool:
try:
search_results = search_with_serpapi(f"\"{chunk}\"")
found = len(search_results) > 0
return found
except Exception as e:
print(f"An error occurred: {e}")
return False In this function, I used my Library SimplerLLM, specifically a method that uses SerperAPI to search on Google from the code.
To access Google’s search engine from your code, you would need an API and its corresponding code. However, using SimplerLLM, the function is already built-in, and you just call it using the “search_with_serpapi” method.
But, you need to generate your API key from their website, create a .env file, and add your key like this:
SERPER_API_KEY = "YOUR_API_KEY"
So, using the above function, each chunk is searched for on Google, and if a result exists, it returns True; otherwise, it returns False.
Step 3: Calculating the Result
Now it’s time to take these Trues and Falses and turn them into a percentage:
def calculate_plagiarism_score(text, chunk_by) -> float:
chunks = chunk_text(text, chunk_by)
total_chunks = len(chunks)
plagiarised_chunks = 0
for chunk in chunks:
if search_chunk(chunk):
plagiarised_chunks += 1
plagiarism_score = (plagiarised_chunks / total_chunks) * 100 if total_chunks > 0 else 0
return plagiarism_scoreThis function works by first calling the chunking method explained in Step 1, and then counting the total number of these chunks.
Using step 2, we determine whether each chunk is available on the web. If it returns True, it increases the count of plagiarized chunks.
After checking all chunks, the plagiarism score is calculated by dividing the number of plagiarized chunks by the total number of chunks, multiplying by 100 to get a percentage. Finally, it returns the plagiarism score as a decimal number(float).
Step 4: Running the Script
All the above methods wouldn’t generate anything if you didn’t give it any input and print the result.
#MAIN SECTION
start_time = time.time()
text = "YOUR_TEXT" # The Input Text
chunk_by = "sentence" # "sentence" or "paragraph"
plagiarism_score = calculate_plagiarism_score(text, chunk_by)
end_time = time.time() # Record the end time
runtime = end_time - start_time # Calculate the runtime
print(f"Plagiarism Score: {plagiarism_score}%")
print(f"Runtime: {runtime} seconds") # Print the runtimeIn this section of the code, you need to enter the text you want to run the plagiarism checker on, pick your preferred method of chunking, and print the results!
You’ll even get the time it took to generate the results (we’ll use it later🤫)
The Role of SimplerLLM
SimplerLLM is an open-source Python library designed to simplify interactions with large language models (LLMs). It offers a unified interface for different LLM providers and a suite of tools to enhance language model capabilities.
I created it to facilitate coding, and it did indeed save me a lot of time. But the main reason I’m using it in this script is that I’m planning on improving this code more and making it detect similarities, too, not just exact copies of the text. So, keep an eye out for the Semantic Plagiarism Checker Post!
Advanced Technique
Now, although the script we created is working properly, why don’t we improve it a little?
For example, when we find that the chunk is available on a webpage somewhere, we can fetch the URLs of these web pages. This simple tweak to the code would make the results of this script a lot more interesting, especially if you turned it into a tool with a nice UI.
Here’s what the new code will look like:
def search_chunk(chunk) -> List[str]:
list = []
try:
search_results = search_with_serpapi(f"\"{chunk}\"")
found = len(search_results) > 0
if (found):
list.append(found)
list.append(search_results[0].URL)
return list
else:
list.append(found)
list.append("None")
return list
except Exception as e:
print(f"An error occurred: {e}")
list.append(False)
list.append("None")
return list
def calculate_plagiarism_score(text, chunk_by) -> float:
chunks = chunk_text(text, chunk_by)
total_chunks = len(chunks)
plagiarised_chunks = 0
counter = 1
for chunk in chunks:
print(f"Chunk {counter} : {chunk} .... {search_chunk(chunk)[0]} .... {search_chunk(chunk)[1]}")
counter += 1
if search_chunk(chunk)[0]:
plagiarised_chunks += 1
plagiarism_score = (plagiarised_chunks / total_chunks) * 100 if total_chunks > 0 else 0
return plagiarism_scoreAs you can see, I edited the “search_chunk” function so that it returns a list containing a True/ False if it found an existing duplicate and the link to the webpage that contains the same chunk. Plus, I added a print statement in the “calculate_plagiarism_score” function to print each chunk, its number, True/False, and the URL of the webpage.
Here’s what the result will look like:

Performance Optimization
A major limitation of the above script is that running it on a large amount of data would be inefficient, like multiple blog posts at a time. What happens here is every chunk will have to be searched for on Google to see if there is existing content that matches it.
So, How can we fix this? There are two approaches we can try.
Approach 1:
The first is leaving the code logic as is but applying parallel programming or multi-threading to it so that it runs on multiple processors, making it much faster. The code will look something like this:
def calculate_plagiarism_score(text, chunk_by) -> float:
"""
Calculates the plagiarism score of a given text by chunking it and checking each chunk for plagiarism in parallel.
"""
chunks = chunk_text(text, chunk_by)
total_chunks = len(chunks)
with ThreadPoolExecutor() as executor:
# Use map to apply search_chunk to all chunks. Results are returned in the order the calls were made.
results = executor.map(search_chunk, chunks)
plagiarised_chunks = sum(results)
plagiarism_score = (plagiarised_chunks / total_chunks) * 100 if total_chunks > 0 else 0
return plagiarism_scoreThe “calculate_plagiarism_score” is the only function that gets updated because all the work is happening in it, so it is the function with the most run-time. Therefore, we apply the ThreadPoolExecuter() to distribute the workload over multiple threads, which decreases the program runtime.
To use this built-in function, you need to import its corresponding module like this:
from concurrent.futures import ThreadPoolExecutor
Now let’s run the normal code and the one we just optimized and see the difference in speed:
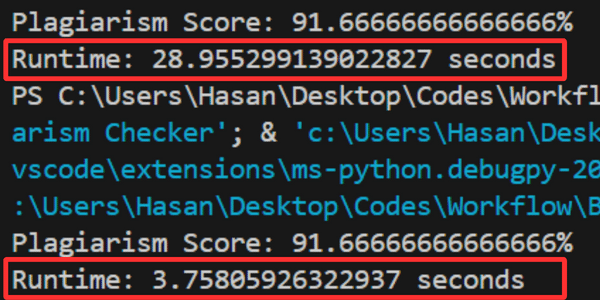
See the difference? The optimized one is almost 10x faster 😲
The normal one took 29 seconds to run, while the optimized one (using threads) took only 4 seconds
Approach 2
The other approach is to decrease the number of search-engine calls and index search results on our local machine somewhere. So, now, instead of searching on the internet, if there is an existing matching chunk, we search in our indexed search results.
Now, if I want to address this approach, it may take like 100 pages, so I’ll leave them for you to experiment 😂
If you tried it, make sure to share it with us, and if you have other better approaches to improve the plagiarism detector, drop it in the comments below!
