
Extract & Analyze YouTube Comments With Python and YouTube API To Boost Your Marketing!

In this post, I will show you how to extract YouTube comments from your channel and turn them into valuable data for your marketing campaigns.
We did something similar with No Code Tools; if you missed it, you can check it here.
But here, we will be doing this without any 3rd parties; we will build this from scratch with Python and the YouTube Data API.
Depending on the data, it can transform your marketing strategy, improve content creation, or even help you increase user engagement.
I’ll guide you through the Python script I wrote to fetch the comments from YouTube. And show you a practical example of how to analyze with AI to boost your online marketing.
How Will We Access These Comments?
This process involves several components, including authenticating with Google’s YouTube Data API, getting the channel ID, and specifying the correct parameters for API requests.
Obtaining Credentials and Channel ID
To access YouTube comments, you first need to authenticate your application with Google:
1. OAuth JSON File
Start by creating a project in the Google Developer Console.
Then, select your project, navigate to the Enabled APIs and Services section, search for YouTube Data API v3, and enable it.
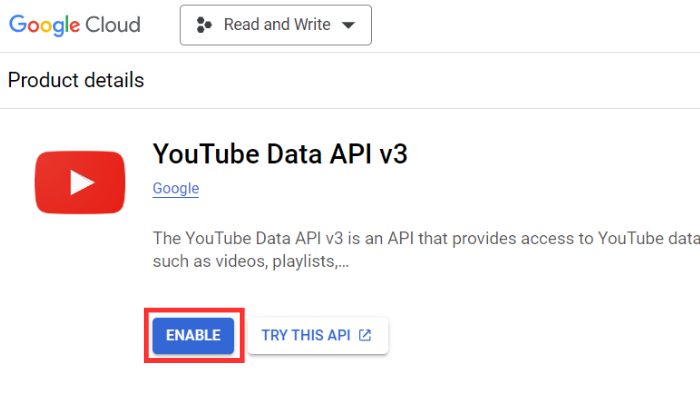
Then, go to the Credentials section and create an OAuth client ID to obtain the clients_secret.json.
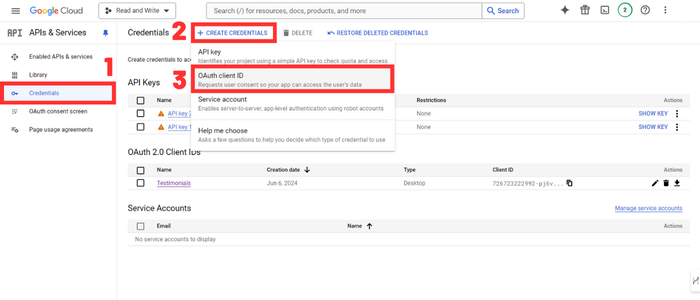
You download this file and put it in the same folder as your Python script. (I’ll give you all the codes later on don’t worry)
2. Channel ID
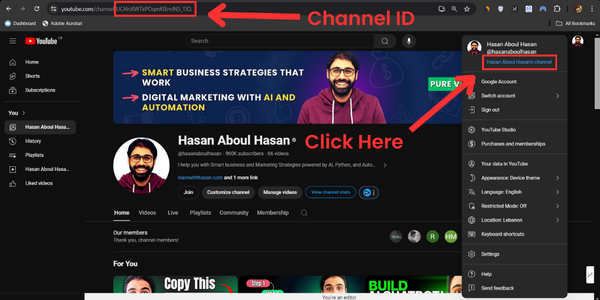
For the code to work, you’ll need to provide your channel ID, which you’ll find when you click on your profile picture on the top right and click on [your_name]’s channel.
Then, it will take you to a page that will provide the channel ID in the URL in this form: youtube.com/channel/{your_channel_ID}
Here’s an example:
The Correct API Call
To fetch comments from the YouTube API, we use specific parameters in our API request to make sure we retrieve the desired data. Here is what our API request will look like:
response = youtube.commentThreads().list(
part="snippet",
allThreadsRelatedToChannelId=channel_id,
maxResults=100,
pageToken=next_page_token,
order="time",
textFormat="plainText"
).execute()
This API has many of functions that have different roles, but in our case, we’ll be using the commentThreads().list To retrieve a list of 100 comments in each API call.
Here are the parameters we’re passing it with:
- Part: This parameter specifies a comma-separated list of one or more commentThread resource properties that the API response will include. In our code, we use
snippetwhich contains the comments and details about them. - AllThreadsRelatedToChannelId: This sets the specific channel ID to fetch comments from all videos in the channel.
- MaxResults: This specifies the number of items (comments with their details) in each response, which we chose to be 100. (this is the maximum number we can choose)
- PageToken: This is used to navigate through paginated results (set of pages), allowing you to continue retrieving comments from the last page you stopped in your previous API call.
- Order: This sorts the comments; we use
timeto get them in chronological order. - TextFormat: Specifies the format of the text in the returned comments; we’ll use
plainText, because it’s easier to read than HTML.
This API request will fetch up to 100 comment threads related to all videos in the specified channel, ordered by time, in plain text format.
This API is free to use as long as you limit your requests do not exceed 10,000 units/day.
But, don't worry I've found 2 loopholes which I'll mention later on that will help you use the API for free even if you have a lot of comments to retrieve which may exceed the 10,000 units you have.
For more details about quota calculation check this reference by google.My Implementation
In simple terms, the script I developed will keep fetching comments from the specified channel until you use all the free 10,000 units you have (or retrieve all the comments on your channel if you have less than 10,000 comments).
Then, it’ll save the date of the comment it stopped at with its corresponding page token, so when you rerun the code once your units reload, it’ll continue fetching from where it stopped last time.
After that, it’ll fetch the privacy status of the videos (public or unlisted) and save the comments with a set of other information about them in a CSV file. (we’ll go over them later on)
Finally, we’ll take each comment and pass it on to OpenAI’s API, which, based on the prompt you create, will do whatever you want it to with the comments fetched.
However, in my case, it’ll return to us whether each comment is testimonial-worthy or not.
In the end, we’ll have a set of comments that are worthy of being testimonials on my website, which we can use in our marketing strategy to gain customers’ trust!
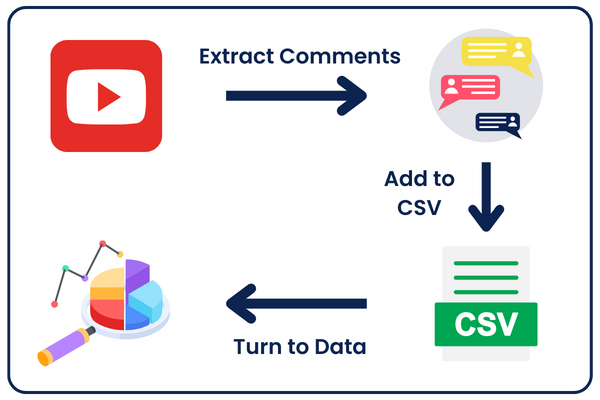
Let’s go over the script step by step to make it easier to understand:
Inputs and Imports
To run the code, you’ll have to enter your inputs and install the necessary libraries used.
Let’s start by creating a virtual environment and installing the libraries.
So, open a new terminal and run the following step-by-step:
1- Create the Virtual Environment:
python - m venv venv
2- Create and Activate the Virtual Environment:
venv/scripts/activate
3- Install Libraries:
pip install google-auth google-auth-oauthlib google-auth-transport google-api-python-client simplerllm
Now, we have a virtual environment with the libraries installed, which will help isolate the project and avoid conflicts between package versions.
After that, you’ll have to enter your Channel ID and the date range of the comments you want to fetch in the Inputs section:
channel_id = 'CHANNEL_ID'
start_date = 'YYYY-MM-DDT00:00:00Z'
end_date = 'YYYY-MM-DDT23:59:59Z'
authentication = get_authenticated_service('YOUR_CLIENTS_SECRET_FILE')
You paste the channel ID in the channel_id variable.
However, regarding the date range, you’ll need to substitute the YYYY with the year, the MM with the month, and the DD with the day. Between the T and Z, it’s the hour of the day (no need to edit it).
Here’s an example of what the date range may look like:
start_date = '2020-01-11T00:00:00Z' end_date = '2023-11-05T23:59:59Z'
This will make the code fetch all the comments between January 11, 2020, 12:00 am and November 5, 2023, 11:59 PM.
But, keep in mind that it’ll start fetching from November 5 2023 till it reaches January 11 2020, so from the newest to the oldest. This is because we used order=”time” in the API call.
Now, regarding the authentication variable, it calls the get_authenticated_service function, which connects to your API using the clients_secret file, which you pass as input.
For example, I saved my clients_secret file as testimonials.json, so I passed it like this:
authentication = get_authenticated_service('testimonials.json')
But how does the get_authenticated_service Function work? Here it is:
Connecting to YouTube’s API (Authentication)
def get_authenticated_service(clients_secret_file):
creds = None
if os.path.exists("token.json"):
creds = Credentials.from_authorized_user_file("token.json", ['https://www.googleapis.com/auth/youtube.force-ssl'])
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
creds.refresh(Request())
else:
flow = InstalledAppFlow.from_client_secrets_file(clients_secret_file, ['https://www.googleapis.com/auth/youtube.force-ssl'])
creds = flow.run_local_server(port=0)
with open("token.json", 'w') as token:
token.write(creds.to_json())
return build('youtube', 'v3', credentials=creds)
When you enter your inputs and run the script for the first time, a tab in your browser will open. Here, you’ll only have to choose the Google account you used to generate the clients_secret file so that Google knows you’re using the API.
Doing this every time you use the code can be quite a drag, right?
That’s why I added something to the code so that when you use an authentication json file for the first time, it saves the fresh credentials in a Token.json file. When you run the code next time, it uses this token to connect to the API directly.
Mechanism of Fetching The Comments
I told you above that you have a limit of 10,000 units per day of free API use, which, in our case, will fetch 9,500-10,000 comments. So, in order to avoid paying for extra credits if you want to fetch more than 10,000 comments, you have two choices:
- You either run your code every day until you fetch all the comments you want to fetch. So, every day, when your limit of 10,000 units reloads, you run the code and fetch 10,000 comments.
- Or, you can create 12 projects in your Google Developer Console (maximum number is 12), generate 12 clients_secret files, and run the code 12 different times, each passing a different json file to the
get_authenticated_service(clients_secret_file)function.
🚨🚨 While the method discussed here is effective for fetching all comments at once, it is not generally recommended as it may violate Google's terms. However, since we're using it for private use and research purposes, this approach can be used.🚨🚨If the 12 projects were still not enough to fetch all the comments, you rerun them the next day.
Now, regardless of the method you choose, you’ll need a mechanism to save the date and page token of the comment you fetched last. That’s the job of these two functions:
def save_state(state):
with open("fetch_state.json", "w") as f:
json.dump(state, f)
def load_state():
try:
with open("fetch_state.json", "r") as f:
return json.load(f)
except FileNotFoundError:
return None
The save_state The function takes the date and the page token of the comment, turns them into json format, and saves them in a fetch_state.json file.
The load_state function loads this json file and passes it to the main function, which uses the data to fetch the comments.
Here’s how they are used in the main function:
def fetch_comments_over_time(authentication, start_date, end_date):
state = load_state()
if state:
next_page_token = state.get("next_page_token")
if state.get("last_fetched_date") != None:
last_fetched_date = state.get("last_fetched_date")
end_date = last_fetched_date
else:
next_page_token = None
So, every time this function is called, it checks if the fetch_state.json contains any data, and if it does, it loads the data and saves them in the next_page_token variable and edits the end_date variable to the date of the last fetched comment.
However, if the fetch_state.json The file is still empty. This means that this is the first time we run the code, so we keep the date range as is and give the next_page_token a value of None so we can pass it to the API request later on.
Now, to the main part of this function:
all_comments = 0
try:
while True:
response = youtube.commentThreads().list(
part="snippet",
allThreadsRelatedToChannelId=channel_id,
pageToken=next_page_token,
maxResults=100,
textFormat="plainText",
order="time",
).execute()
for item in response['items']:
comment = item['snippet']['topLevelComment']['snippet']['textDisplay']
user_name = item['snippet']['topLevelComment']['snippet']['authorDisplayName']
user_image = item['snippet']['topLevelComment']['snippet']['authorProfileImageUrl']
date = item['snippet']['topLevelComment']['snippet']['publishedAt']
video_id = item['snippet']['videoId']
video_privacy = fetch_video_privacy(youtube, video_id)
if date < start_date:
raise Exception("Date out of range")
if start_date <= date < end_date:
writer.writerow([comment, user_name, user_image, video_id, video_privacy, date, '']) # Write each comment as fetched
last_fetched_date = date
all_comments = all_comments + 1
print(all_comments)
save_state({
"next_page_token": next_page_token,
"last_fetched_date": last_fetched_date,
})
next_page_token = response.get('nextPageToken')
if next_page_token:
print("Next Page Toke: " + next_page_token)
if not next_page_token:
print("No more comments.")
break
except Exception as e:
print(f"Error during comment fetch: {e}")
Here’s the main engine for fetching the comments. Is it quite confusing? Don’t worry; I’ll break down the details for you.
Let’s start with the main structure; as you can see, we have a while(true) loop that goes over the whole code and keeps fetching comments until it either faces an error (most probably the error of exceeding the quota limit), which stops the code by entering the except Exception as e: line of code.
OR, it iterates into a comment where its date is before the start date already specified in the inputs section.
OR, it iterates into an empty next_page_token, which means that there are no more pages to check and no more comments to fetch.
However, regardless of encountering any unexpected errors, all the comments you have already fetched will already be saved in the CSV file with the date and next_page_token in the fetch_state.json, so you can run the code again and continue fetching from the last comment you fetched. Here’s the part of the code that saves the state:
save_state({
"next_page_token": next_page_token,
"last_fetched_date": last_fetched_date,
})
And this is the part that writes the comments with its details in the CSV:
writer.writerow([comment, user_name, user_image, video_id, video_privacy, date, '']) # Write each comment as fetched
So, in every loop, we’re getting the video details and saving them in the CSV directly so we don’t miss any comments due to any unexpected errors.
However, we only save the comment if it’s within the date range we already specified in the input section. Otherwise, we will continue looping until the comment’s date is before the start date specified in the input.
Now, in regard to the video details, we’re getting the API response, which contains a list of 100 comments, and fetching each comment with its respective details directly in the for loop:
for item in response['items']:
comment = item['snippet']['topLevelComment']['snippet']['textDisplay']
user_name = item['snippet']['topLevelComment']['snippet']['authorDisplayName']
user_image = item['snippet']['topLevelComment']['snippet']['authorProfileImageUrl']
date = item['snippet']['topLevelComment']['snippet']['publishedAt']
video_id = item['snippet']['videoId']
video_privacy = fetch_video_privacy(authentication, video_id):
All the video details we want can be found in the response returned by the commentThreads().list() except for the video_privacy of the video, which returns if the video is public or unlisted.
So, in order to fetch the video privacy, we need to use another API call that returns this data. To do that, we’ll call the fetch_video_privacy_status function:
def fetch_video_privacy(authentication, video_id):
try:
request = authentication.videos().list(
part="status",
id=video_id
)
response = request.execute()
items = response.get('items', [])
item = items[0]
privacy_status = item['status']['privacyStatus']
return privacy_status
except Exception as e:
print(f"Error fetching details: {e}")
return None
This function uses the videos().list() API call, which takes different parameters and returns a different response than the commentThreads().list() we used above.
So, like this, we have all the details we need for every comment, and we directly write it in the CSV file, as I showed you above.
Turning the Comments Into Testimonials
After you fetch all the comments, now it’s time to turn these comments into useful data!
Since this part should be executed after fetching all the comments, I’ll open a new Python file to avoid mixing the codes.
First things first, we’ll need to create a .env file and add our OpenAI API to it in this form:
OPENAI_API_KEY = "YOUR_API_KEY"
Now it’s time for the code:
import csv
import time
from SimplerLLM.language.llm import LLM, LLMProvider
from SimplerLLM.tools.file_loader import read_csv_file
def is_testimonial_worthy(comment):
llm_instance = LLM.create(provider=LLMProvider.OPENAI, model_name="gpt-3.5-turbo")
my_prompt = f"""You are an expert in comment analysis. Evaluate if this YouTube comment is worthy
of being a testimonial on my website. Only consider positive testimonials. Return True or False.
Comment: {comment}
"""
response = llm_instance.generate_response(prompt=my_prompt)
return response
start = time.time()
file = read_csv_file("youtube_comments.csv")
counter = 0
with open('my_data.csv', 'a', newline='', encoding='utf-8') as csvfile:
writer = csv.writer(csvfile, delimiter=',', quotechar='"', quoting=csv.QUOTE_ALL)
if csvfile.tell() == 0:
writer.writerow(['Comment', 'User', 'Profile Picture', 'Video ID', 'Video Privacy', 'Time', 'Testimonial Worthy'])
for row in file.content[1:]:
testimonial = is_testimonial_worthy(row[0])
row[6] = testimonial
writer.writerow([row[0], row[1], row[2], row[3], row[4], row[5], row[6]])
counter = counter + 1
print(counter)
end = time.time()
print(end-start)
This code opens a new CSV file, reads the comments from your main CSV, runs the is_testimonial_worthy function on each comment and saves the value in the new CSV file.
To do that easily, I used the SimplerLLM library, which Hasan developed, which makes coding A LOT EASIER.
Now, in the Testimonial Worthy field of every comment, I’ll have a True or False value that tells me whether this comment is worthy of being a testimonial on my website.
If you want to get a different type of data from these comments, just edit the my_prompt variable, which contains the prompt we’ll use to call the OpenAI API. Then, you’ll get your desired result.
If you’re a beginner with writing prompts, check out this full free guide on how you can write prompts the right way. And, if you want to become a professional “A Prompt Engineer” (Sounds nice, huh 😏😂), check the full course, which will also give you access to a set of power prompts!
Remember that obtaining testimonial worthiness from comments is only one example of what you can do with them.
You can, for example:
- Get the negative comments
- Get the comments that contain mentions of other brands
- Get the comments that are spam
- Get the positive comments
- Ge the comments that are useful for building a FAQ database
- Etc…..
Literally, there are never-ending ideas as to what you can do with this. So, get into a hot tub, relax, and let these 1 million dollar business ideas flow in 😂
The Codes
I told you I’ll give you all the codes, and I’m a man of my word!
Here are the 2 Python files; put them in the same folder, create the .env file in the same folder, and you’re all set!
Don’t forget if you face any problems, we’ll be there to help you on the forum!
The Results
Of course, I already tried the code on my dataset and got pretty amazing results!
I took Hasan’s Channel as the input channel and fetched all the comments on his channel between June 2024 and April 2018. It took about four days to extract them. Every day, I executed the code using two projects I created on my Google Developer Console, so I had a quota of 20,000 units per day, and I extracted 85,000 comments.
I could’ve just created ten projects on my account and extracted all the comments on the same day, but the other projects were already in use.
Here is a small part of the CSV File:
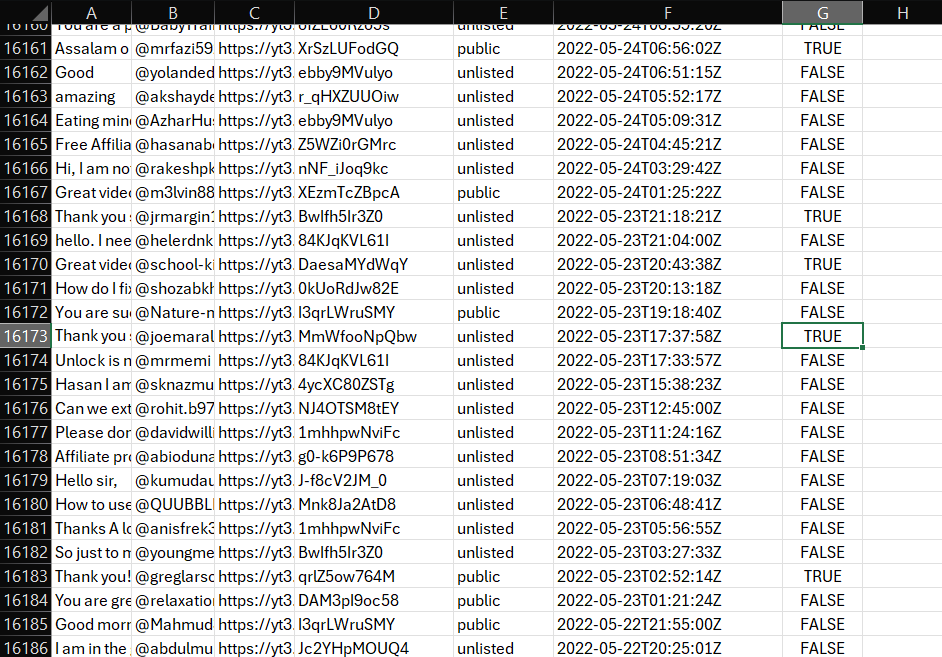
As you can see, I fetched every comment with the user name, image URL, video ID, video privacy, and video date, and then once I ran the testimonial-worthy code, every comment got a True/False result whether it was worthy of being a testimonial or not.
Pretty cool, huh?
I filtered the comments to get only the testimonial-worthy ones, and here are some of them that I got at the end:
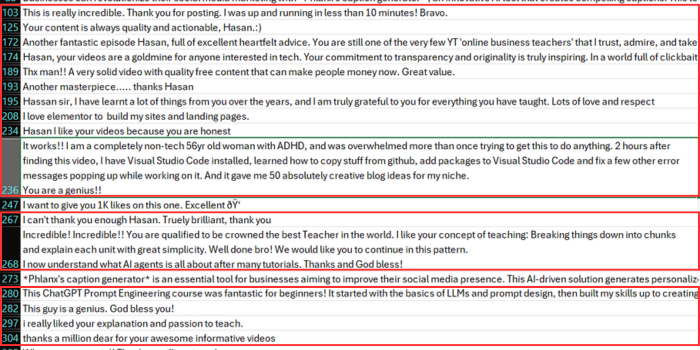
As you can see, out of all the comments shown, only numbers 273 and 208 were not testimonial-worthy. If I had written the prompt in a better way, I would’ve gotten better results, maybe 99% success.
But, still, that’s a very good result!
Don’t forget to play around with the prompt. These comments are literally a gold mine; you can get very valuable data from them.
Happy coding 🙂





Responses